Hat jemand Erfahrung damit, ob sich bei einem gegebenen PDF-Input, bei dem einzelnen “Kapitel” mit Lesezeichen im PDF markiert sind, Strukturelemente erstellen lassen?
oder kennt jemand gute Wege um ggf. das PDF im Vorfeld zu manipulieren, dass bspw. aus einer Lesezeichenliste ein Inhaltsverzeichnis wird?
Oh, da habe ich mich selbst überspielt.
Bookmarks im PDF ==> “ToC” für Strukturdatenerstellung.
Die Konfiguration im Plugin für diese Strukturextrahierung findet sich in diesem Knoten. Wie das aber genau funktioniert, ist mir schleierhaft, die Doku verrät hier auch nicht allzu viel. Der Standardwert in der Konfiguration sieht folgendermaßen aus:
<docType>
<parent>Chapter</parent>
<children>Chapter</children>
</docType>
Ich habe ein Beispiel eines Amtsblattes, vorliegend als Jahrgangsband (PDF) mit Bookmarks auf die jeweiligen Ausgaben.
Bei der Standardkonfiguration wie oben gezeigt, wird mir dann im Strukturbaum des Amtsblattes (Periodical - PeriodicalVolume) als Unterlement ein “Kapitel” und dann weitere Kapitel für die jeweiligen Bookmarks mit Label des Bookmark als Titel angelegt.
Mit der Konfig
<docType>
<parent>PeriodicalIssue</parent>
<children>PeriodicalIssue</children>
</docType>
entsteht untenstehender Baum. Das ist natürlich falsch, die einzelnen “Hefte” sollten direkt im Band sein. Die Konfiguration ist natürlich schon absurd.
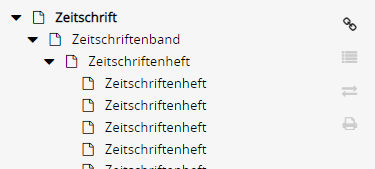
Baue ich aber auf das “logischere” Konfiguration mit PeriodicalVolume als parent und Issue als children kommt es zur Fehlermeldung:
Child of type 'PeriodicalVolume' is not allowed for parent; unfortunately we don't have any information about the parent
-
Dieses “leere” Parent-Chapter bräuchte ich egtl. nicht, es sollten alle Bookmarks gleich als Tochterlement von PeriodicalVolume eingefügt werden. Am besten als PeriodicalIssue.
-
Ein generelles Problem an der gegenwärtigen Konfiguration scheint mir, dass diese global wirkt, d.h. wenn ich das nächste Mal ein PDF einer Monographie mit Kapitelstruktur importiere, müsste ich zuvor die XML-Konfig anpassen, damit nicht Zeitschriftenhefte angelegt werden, anstelle der Kapitel. “Neuere” Plugins erlauben hier ja Projekt/Vorlagen-bezogen zu differenzieren. Das scheint mir beim PDF-Extraction-Plugin nicht der Fall zu sein, oder?
Ach du meine Güte… Man lese die Doku immer und immer wieder, irgendwann versteh ich sie dann auch… 
So mein Problem ist gelöst, wenn ich das Parent-Element in der Config weglasse, und nur die gewünschten PeriodicalIssue-Elemente erstellen lasse.
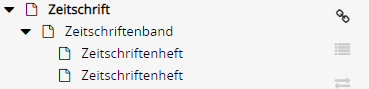
Ich entschuldige für das Rauschen im Forum durch diesen Thread…
1 „Gefällt mir“
Hi 
die Konfiguration der Strukturelemente ist zugegebenermaßen etwas undurchsichtig. Ich werde das mal zum Anlass nehmen, die Kongiguration und die Dokumentation dazu etwas gerade zu ziehen
3 „Gefällt mir“
Nach mehrmaligem Lesen und Ausprobieren habe ich es ja hinbekommen, und ich bin ein sehr, sehr schlechter Doku-Versteher.
Danke auch für den Hinweis, dass das PDF-Extraction-Plugin seit kurzem in der neuesten Version sensibel auf Projekte und Templates reagieren kann. Ich werde das ausprobieren.